



Learn how to integrate easily your custom deployed LLM models on AWS Sagemaker into your Langchain codes.
Introduction
In this blog post, we will see how to integrate a custom LLM endpoint deployed through AWS Sagemaker with Langchain.
Be sure to read our post on deploying your own LLM endpoint with Sagemaker (the link is here). We will continue it here. We are going to go faster on the Sagemaker side of things as everything has been explained in the other articles. So don’t forget to read it and have it ready.
More precisely, you will learn in this post, to:
- What is Sagemaker?
- What is Langchain?
- Connect a sagemaker LLM endpoint with langchain
- Create a basic chat with langchain and your deployed LLM endpoint
You can find the tutorial code here. Don’t forget to star the repo if you like it.
What is AWS SageMaker ?
AWS SageMaker is a cloud service provided by AWS that helps users easily build, train, and deploy machine learning models AND that can be used to deploy LLM models.
It is designed to simplify the complex infrastructure part of ML project or LLM project and allows users to go straight for the use case.
It will allow you to:
- Build: SageMaker provides various tools and integrated Jupyter notebooks to help users prepare their data and develop their machine learning models.
- Train: Once the model is ready, you can train your models at scale (with all your data) without managing the underlying infrastructure. This means you do not need to do all the tedious task about handling GBs of data that you needed to do before (believe me, it was not this fun!).
- Deploy: After training, you can deploy your models for inference easily. SageMaker handles the deployment process, scaling the infrastructure as needed to meet demand. That means you need to care a little “less” on how much your model will be used.
As an LLM model is in fact a Machine Learning model, you can use this service to deploy LLM. There are even big partnership between AWS and big LLM players like Anthropic or HuggingFace.
What is Langchain ?
Langchain is a framework designed to facilitate the creation and deployment of applications powered by large language models (LLMs). It provides a modular set of tools and integrations that allows easier integration of LLMs with the ecosystem. Basically, it allows you to create chains (or pipelines) which are sequence of multiple tasks and connections to a wide variety of systems.
Here’s some possible use cases with Langchain:
- Connect to Google search and your own vector store and send a mail to with the news of each field to your clients
- Analyse meeting videos to get the text and put it inside a vector store and create a knowldege graph and have a living documentation
- Have a chat where you can ask to do something and it will automatically choose which service to leverage and launch process, for example for ticketing system
The use case I wrote about are only the tip of the iceberg and this is possible only because of Langchain’s wide integration and chain like system.
Prerequisites
We will now begin the tutorial. But before that, be sure to check the prerequisites:
- A functional AWS account where you have admin permission (check this link)
- An AWS user set up on you laptop (check this link)
- Having done the previous article on how to deploy an LLM on Sagemaker (here’s the link). We will begin this tutorial as if you have done it.
Langchain + Sagemaker
Ok now that everything is explained and ready, let’s go straight to the point.
Prepare the environment
We will use the same setup as before, meaning Jupyterlab for the coding and Pipenv for managing virtual env. To have better readability, we will create a new folder called langchain-llm-sagemaker-endpoint and copy inside it all the files I need from the previous post (and rename some).
mkdir langchain-llm-sagemaker-endpoint
cp deploy-llm-sagemaker-endpoint/deploy-llm-sagemaker.ipynb deploy-llm-sagemaker-endpoint/Pipfile langchain-llm-sagemaker-endpoint/
cd langchain-llm-sagemaker-endpoint
mv deploy-llm-sagemaker.ipynb langchain-llm-sagemaker-endpoint.ipynb
Add langchain library
Now that the environment is ready, let’s add the langchain library:
pipenv install langchainThis would have nicely created the Pipfile.lock and added the library. Now we deploy the LLM model.
Deploy the LLM model
Let’s deploy the model now. First we will launch the Jupyter Lab:
pipenv run jupyter labThis would have launched browser tab with the Jupyter Lab. Don’t forget to choose the correct kernel when you open the notebooks:
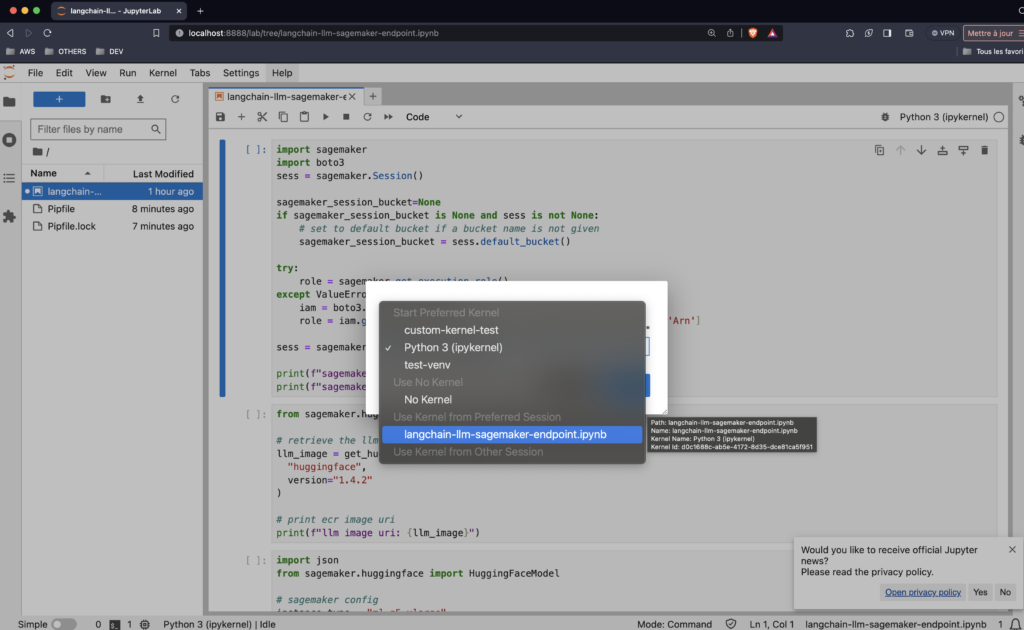
No run all the cells except the last (that one will kill your endpoint). This will take 10 minutes but you will have your Mistral 7B ready.
Now that the model is done, let’s spice things with Langchain.
Langchain with Sagemaker endpoint
One of the great thing about langchain is that it has integration for so many technologies. And also for Sagemaker Endpoint, so let’s use it.
First, create a new cell and add this:
from langchain_community.llms import SagemakerEndpoint
from langchain_community.llms.sagemaker_endpoint import LLMContentHandlerThis will import the required code inside Langchain:
from langchain_community.llms import SagemakerEndpointfrom langchain_community.llms import SagemakerEndpoint-> This will import the Langchain implementation of the Sagemaker Endpoint connection. All the magic is there.from langchain_community.llms.sagemaker_endpoint import LLMContentHandler-> This is another utility that will handle how the input and output of the LLM are processed. This allow you to finely process them but we will use a super simple usage.
Now, let’s create the client:
client = boto3.client('sagemaker-runtime', region_name=sess.boto_region_name)It is the client that will link Langchain to the Sagemaker endpoint and will give it all the required permissions. It is inside that you will have all the credentials for your AWS account (securely of course).
Now let’s implement the content handler:
class ContentHandler(LLMContentHandler):
content_type = “application/json”
accepts = “application/json”
class ContentHandler(LLMContentHandler):
content_type = "application/json"
accepts = "application/json"
def transform_input(self, prompt: str, model_kwargs) -> bytes:
input_str = json.dumps({"inputs": prompt, "parameters": model_kwargs})
return input_str.encode("utf-8")
def transform_output(self, output: bytes) -> str:
response_json = json.loads(output.read().decode("utf-8"))
return response_json[0]["generated_text"]Here’s what this code does:
class ContentHandler(LLMContentHandler)-> this will create a class called ContentHandler that will inherit all the good stuff of LLMContentHandler so that you do no need to implement it again.def transform_input-> this define processing done when you input data to the LLM. Here, you just create a dict with everything needed. You could for example add other parameters or do specific processing depending of the LLM model.def transform_output-> this define the output processing. Here we just return a parameter of the output but you could do so much more.
Now let’s create the Langchain Sagemaker endpoint:
content_handler = ContentHandler()
sagemaker_llm = SagemakerEndpoint(
endpoint_name=llm.endpoint_name,
client=client,
model_kwargs={"temperature": 0.1},
content_handler=content_handler,
)Here’s what this code do:
content_handler = ContentHandler()-> this create an instance of your class ContentHandler that Langchain will need to communicate with the LLM endpoint.sagemaker_llm = SagemakerEndpoint-> This will create the Langchain object to communicate with the Sagemaker Endpoint. You can see that we are using the client and the content_handler from before.
Now everything is ready to use our LLM:
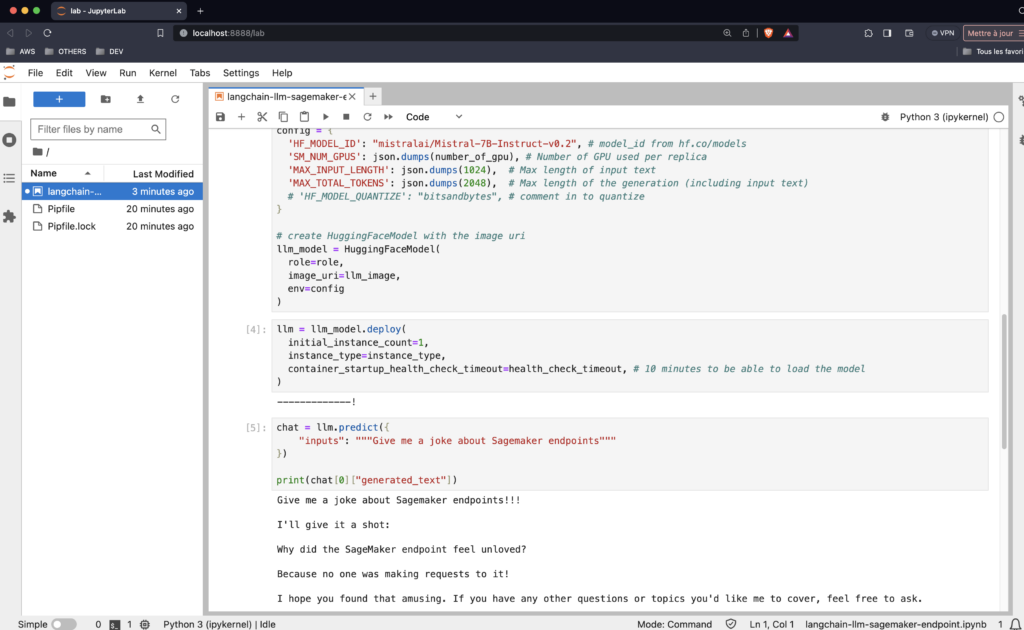
response = sagemaker_llm.generate(prompts=["Give me a joke about Sagemaker endpoints"])
print(response)You will have a not an answer like this:
generations=[[Generation(text=”Give me a joke about Sagemaker endpoints\n\nSure, here’s a light-hearted joke about Amazon SageMaker endpoints:\n\nWhy did the Amazon SageMaker endpoint go to therapy?\n\nBecause it had low self-confidence and kept second-guessing its predictions!\n\nOf course, in reality, Amazon SageMaker endpoints are highly confident and accurate, providing real-time predictions for machine learning models that can be integrated into applications and workflows.”)]] llm_output=None run=[RunInfo(run_id=UUID(‘3e189aca-ad3c-45d3-9b17-bb442acf2fc8’))]
So let’s format it a little. As you can see, the output is an object and what we want is the text field inside all this so let’s get it:
print(response.generations[0][0].text)Give me a joke about Sagemaker endpoints
Sure, here's a light-hearted joke about Amazon SageMaker endpoints:
Why did the Amazon SageMaker endpoint go to therapy?
Because it had low self-confidence and kept second-guessing its predictions!
Of course, in reality, Amazon SageMaker endpoints are highly confident and accurate, providing real-time predictions for machine learning models that can be integrated into applications and workflows.You did it! Congratulations. You just connected to Langchain your own LLM model deployed with AWS Sagemaker. It is this easy to do that. That is why Langchain and Sagemaker are magic (when you know how to use them), it allow you to do very complicated things easily.
Clean up
Now that you played to your heart’s content, don’t forget to destroy your endpoint, it is not cheap by any measure:
llm.delete_model()
llm.delete_endpoint()Conclusion
Let’s conclude our tutorial here. You just learned to connect with Langchain to your own LLM models hosted on AWS Sagemaker. This is really great.
This setup will allow you to test many open source models or even fine-tuned models for your own use cases and not be completely blocked with the LLM services like OpenAI and AWS Bedrock.
We deployed only a small 7B model but with some perseverance (and some money), you could even deploy a sate-of-the-art LLM like 8x7B Mistral which is insanely good and fast. Only the sky is the limit.
Afterward
I hope this tutorial helped you and taught you many things. I will update this post with more nuggets from time to time. Don’t forget to check my other post as I write a lot of cool posts on practical stuff in AI.
Cheers!